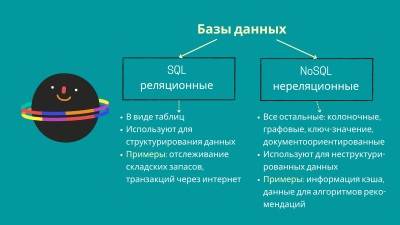
Что такое извлечение признаков и зачем оно нужно?
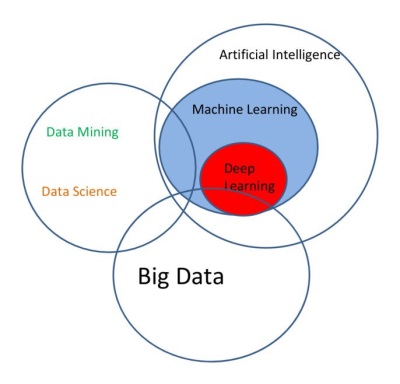
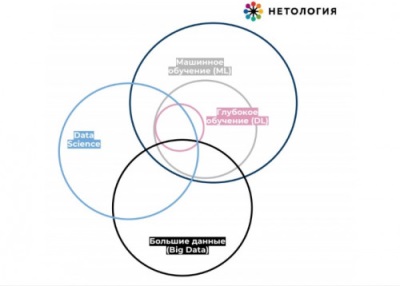
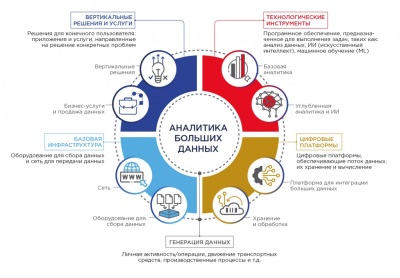
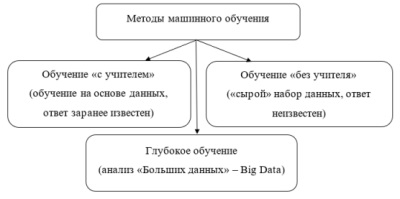
Извлечение признаков - это процесс выделения наиболее значимых и информативных характеристик из множества данных. В задачах анализа данных и машинного обучения извлечение признаков является важным этапом, поскольку оно позволяет преобразовать исходные данные в формат, который может быть обработан и использован алгоритмами машинного обучения.